Initiation à git
Git Kezaco

Git a été crée pour aider le projet de Linus Torvald Linux à être durable avant l’apparition de git les modifications apportées au projet Linux ont été transmises sous forme de correctifs et de fichiers archivés jusqu’en 2002 ou le projet utilisa un outil similaire à git BitKeeper. Mais suite à l’éffondrement de la société. Linus Torvald créa son propre outil appelé git.
L’objectif de git est pouvoir gérer les différentes versions du programme au fils de son évolution.
Un des exemples d’autre outil similaire encore actuellement utilisé est:
- SVN
Pourquoi git
Git à plusieurs avantages:
- Il est simple d’utilisation
- Il est rapide
- Il est décentralisé
- Il est capable de gérer un important nombre branches d’un même travail
- Il permet de conserver les diverses modifications d’un travail
- Il permet le travail en équipe
- Il permet d’intégrer une CI qui va vérifier le travail
Le langage de base
Dans ce tuto les termes liés à git vont être expliqués ici:
- commit: on parle de commit l’ensemble des modifications effectuées un temps T et validé par la personne ayant rédigé son contenu.
- branch: Une branche représente une ligne de développement indépendante.
La ligne de développement est une suite de commit.
La branche principale sera appelé la branche master. Toutes les autres branches dériveront de cette branche.
Aide
Pour commencer git possède une aide très complète permettant d’apprendre ou se remémorer facilement son utilisation:
git helppour l’aide généralgit help <command>pour une aide précise
Ces commandes sont en réalité un alias sur man git-<command>
Configuration
Maintenant il est important d’avoir une bonne configuration dans cette section seule les configurations générales vont être présentées, mais d’autres configurations vont arriver par la suite…
Pour identifier les commits il est obligatoire de configurer son Nom et son
Email pour ne plus être embêté on va le configurer globalement à l’aide du mot
clé --global.
git config --global user.name "<name>"
git config --global user.email "<email>"De plus je vous conseille de configurer l’éditeur utilisé par défaut si vous n’êtes pas à l’aise avec vi.
git config --global core.editor <editor>La base
Maintenant que la configuration est faite, il va être possible de commencer son premier projet. Pour cela on va commencer par créer un projet et l’initialiser:
$ mkdir <my_project>
$ cd <my_project>
$ git init
Initialized empty Git repository in .../<my_project>/.git/Les étapes pour l’ajout d’un élément au versionning

Pour vérifer le status des différents éléments on pourra utiliser la commande
git status.
Dans l’exemple suivant on creer un fichier test:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
test
nothing added to commit but untracked files present (use "git add" to track)
$Donc pour l’ajout d’un fichier on devra:
$ git add <file>
$Dans notre exemple:
$ git add test
$Quand on vérifie le status on obtient maintenant:
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: test
$On va maintenant faire notre premier commit. Pour cela vous pouvez soit faire
git commit et fenêtre va s’ouvrir avec un recapitulatif de vos modifications
qu’il est possible de modifier et vous pouvez écrire votre message permettant
de reconnaitre votre commit.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# On branch master
#
Initial commit
#
# Changes to be committed:
# new file: test
#Ou il est possible de le faire en une ligne comme je préfère le faire:
$ git commit -m 'Initial commit'
1 file changed, 1 insertion(+)
create mode 100644 test
$Maintenant git status nous dira qu’il n’y a plus rien à faire votre commit a
été fait.
$ git status
On branch master
nothing to commit, working tree clean
$petit tip:
si vous avez envie d’ajouter qu’une partie d’un fichier je vous
conseille de creuser du côté de commit -p
Il est alors possible de le voir apparaitre dans les logs montrant l’ensemble des commit fait sur la branche actuelle.
$ git log
commit a764b99ef48b507b344a46ae47fa8469b6405b22 (HEAD -> master)
Author: Benoit Forgette <[email protected]>
Date: Sat Apr 4 18:26:25 2020 +0200
Initial commit
$Les remotes
Pour le moment l’ensemble du travail effectué est en local mais il serait intéressant de le mettre en ligne et de pouvoir récupérer les données en ligne sur notre machine local.
Pour cela on va ajouter une remote:
$ git remote add <name> <url>
$- name est le nom qui va permettre de l’identifier
- url est l’adresse du serveur distant
Dans notre exemple on va mettre un repository local:
$ git remote add test /home/noname/tuto_git/server/test1.git
$Pour visualiser la remote ajouté:
$ git remote -v
test /home/noname/tuto_git/server/test1.git (fetch)
test /home/noname/tuto_git/server/test1.git (push)
$Maintenant, pour le besoin du test on va crée le serveur en clonant le repo
actuel au lieu de notre remote.
On se déplace jusqu’au chemin: /home/noname/tuto_git/server, puis:
$ git clone --bare /home/noname/tuto_git/test1/
$Il est maintenant possible de push notre commit sur notre serveur:
$ git push test
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Writing objects: 100% (3/3), 246 bytes | 246.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To /home/noname/tuto_git/server/test1.git
a764b99..df347da master -> master
$Maintenant si nous étions plusieurs à travailler dessus comment faire! On va cloner notre repository grâce à:
$ git clone /home/noname/tuto_git/server/test1.git
Cloning into 'test1'...
done.
$nous pouvons modifier un fichier on le commit puis on le push et plus qu’a
attendre que l’autre collaborateur récupère les modifications grace à git pull
Mais avant cela on ne peut pas continuer sans parler de la différence entre rebase et merge
Rebase vs Merge
Lorsque que l’on pull des commits il y a 2 stratégies qui existe soit on merge:

C’est à dire que lors du merge un nouveau commit merge va être écrit si des conflits entre 2 commit apparaisse par exemple si vous avez modifié le même fichier en même temps.
Soit la stratégie du rebase qui elle va permettre la modification des commits qui pose problème tout en conservant l’ensemble des commits qui a été fait.

Je vous conseille grandement d’appliquer la stratégie de rebase pour avoir un travail plus propre même si la stratégie du merge est plus facile à gérer.
Pour changer sa stratégie générale, vous pourrez:
# pour ce repo ci
$ git config pull.rebase true
# pour tous les repos
$ git config --global pull.rebase truesi vous voulez appliquer sporadiquement cette stratégie vous pouvez:
$ git pull --rebaseVous avez à présent les bases pour commencer à utilisé git
Les logs
Approfondissant un peu plus toutes les infos que git peut nous apporter sur notre travail actuel.
Nous avions vu git log pour visualisez tout les commit de la branche actuelle
mais il est possible d’avoir une version raccourcie avec git log --oneline.
ou pouvoir voir de quelle branche proviens les commits grace à git log --graph
Shortlog
Il est possible d’avoir un résumé des commit par personne grace à git shortlog
Comme par exemple le shortlog du projet jefferson
$ git shortlog
Dominic Chen (3):
fix spelling errors, convert tabs to spaces
add support for extracting block and character devices
add support for JFFS2_COMPR_ZERO
Stefan (4):
bugfixes, -f parameter, error handling
fixed and moved rtime
added JFFS2_COMPR_LZMA support (used by OpenWRT)
added installer
Stefan Viehböck (9):
Initial commit
Update README.md
Update README.md
Update README.md
Update README.md
Merge pull request #1 from firmadyne/master
Fix regression caused by 31ce40d82b146a9e735ee6c858b8d1b042a40329
Fix typo
Add exception handler for OSError (os.mknod)
sviehb (1):
Initial commit
$Show
git show <commit> va permettre de visualiser ce qui a été modifié dans un
commit précis ou commit est le sha permettant d’identifier le commit:

Diff
git diff <commit1> <commit2> va permettre de comparer les modifications
faites entre les 2 commits.
Les opérations shell de base avec git
Lorsque l’on supprime ou on déplace un fichier il est conseillé d’utiliser les commandes git pour éviter que git perdre la track de ses fichiers la.
- git rm
- git mv
Les conflits
Les conflits sont une partie intégrante de la vie d’un projet git et vous y passerez du temps alors être efficace dans cette partie la est importante!
Lorsque vous aurez un conflit vous devriez avoir ce genre de message:
$ git pull --rebase
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Total 3 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
From /home/noname/tuto_git/server/test1
df347da..4ae5af4 master -> origin/master
First, rewinding head to replay your work on top of it...
Applying: .
Using index info to reconstruct a base tree...
M test
Falling back to patching base and 3-way merge...
Auto-merging test
CONFLICT (content): Merge conflict in test
error: Failed to merge in the changes.
Patch failed at 0001 .
hint: Use 'git am --show-current-patch' to see the failed patch
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".
$pour voir les conflits vous pourrez utiliser la commande:
$ git am --show-current-patch
commit a952fa485e4b2d4fcc5284e7855e14c220f97617 (master)
Author: Benoit Forgette <[email protected]>
Date: Sat Apr 4 20:10:31 2020 +0200
My commit
diff --git a/test b/test
index 02dc432..a71b06e 100644
--- a/test
+++ b/test
@@ -1 +1 @@
-test
+modif
$Lorsqu’il y a des conflits git crée dans les fichiers des marqueurs de conflits pour être sur d’en avoir oublié aucun il est fortement conseillé d’utiliser la commande:
$ git diff --check
test:1: leftover conflict marker
test:3: leftover conflict marker
test:5: leftover conflict marker
$Cette commande indiquequera si des marqueurs ont été oubliés et ou.
pour régler le conflit vous aurez juste à modifier le fichier concerné et de l’ajouter. comme l’exemple suivant:
$ git add test
$ git rebase --continue
Applying: My commit
$si vous avez fini git status devrez vous informer que tout est normal.
Une fonctionnalité un peu cachée de git mais que j’affectionne tout particulièrement est:
git config rerere.enabled truecette fonctionnalité va permettre de sauvegarder dans le répertoire
.git/rr-cache l’ensemble des résolutions de conflit permettant si un conflit
se représente de le résoudre automatiquement. L’explication étant un peu
compliquée et étant très bien expliquée
ici, je ne vais pas
m’attarder sur le sujet.
Les branches
Passons au choses sérieuses une des grandes puissances de git est son système de branche.

Pour l’instant on s’est baladé seulement sur la branche master. Mais, il est temps
de découvrir les autres. Lorsque l’on crée une branche, c’est dans le but de
pouvoir avancer des fonctionalités sans impacter l’ensemble du projet.
Quand la fonctionalité est terminée on pourra soit la rebase soit la merge avec
la branche principale.
Pour ma part ma façon de travailler est la suivante:
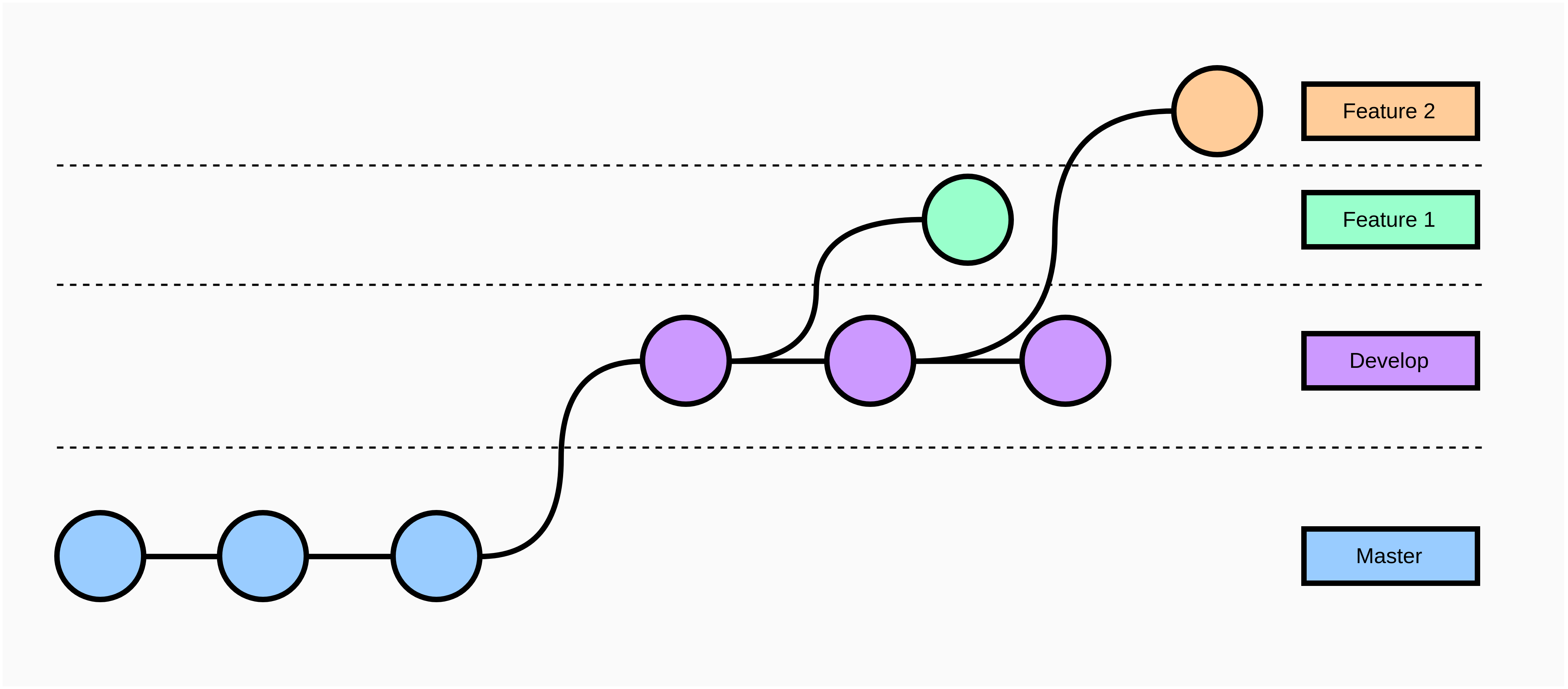
Je garde toujours ma branche master clean, c’est la branche qui fonctionne et la branche develop est la branche sui va subir tout les rebase me permettant de quand je veux mettre en production la branche master va recevoir l’ensemble de mes commit sans conflit.
Pour créer une branche, j’utilise 2 façons: Cette technique permet de créer la branche sans se déplacer dessus.
$ git branch test
$ git branch
* master
testCette technique permet de créer la branche en se déplaçant dessus.
$ git checkout -b test
Switched to a new branch 'test'
$ git branch
master
* testVous avez pu voir que pour visualiser les branches locales j’ai utilisé
git branch. Mais si vous voulez voir les branches distantes vous pouvez
utiliser git branch -a
Maintenant quand on veut resynchroniser nos deux branches on va soit rebase soit merge (cf merge vs rebase).
Rebase
Pour rebase sur master:
$ git checkout master
$ git rebase <feature>
First, rewinding head to replay your work on top of it...
Fast-forwarded master to <feature>.
$Si on souhaite etre explicite on peut aussi:
$ git rebase --onto master <feature>
First, rewinding head to replay your work on top of it...
Fast-forwarded master to <feature>.
$Merge
Pour merge on va utiliser la commande suivante:
$ git checkout master
$ git merge toto
Updating 9aa88d6..0fa442c
Fast-forward
test | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
$Suppression de la branche
Quand on fini avec une branche on a l’habitude la supprimer pour cela on utilise:
# pour la suppression seulement en local
$ git branch -d <branch>
Deleted branch test (was 13f6ab4).
$
# pour la suppression sur le serveur et en local
$ git branch -D <branch>
Deleted branch test (was 13f6ab4).
$Hmm.. Hmm.. Vous me diriez surement que j’ai oublié quelque chose comment on revient sur la branche master. Pour cela rien de plus simple:
$ git checkout master
Switched to branch 'master'
$Les déplacements
Comme vous avez pu le comprendre avec la dernière commande git checkout permet de se déplacer mais cela ne permet pas seulement de se déplacer entre branche mais aussi entre commit. Imaginer que vous ayez oublié de commencé une feature à partir d’un certain commit eh bien aucun problème voici un exemple:
$ git checkout <commit>
Note: checking out '<commit>'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at <commit> commit 2
$ git checkout -b <feature_special>
Switched to a new branch '<feature_special>'Les Hook
Les Hook sont surement une feature que je préfère dans git.

Les hook permettent de programmer une action à effectuer lors du passage d’une différente étape présenté plus haut et elle peut être mise en place aussi du coté serveur c’est d’ailleurs de cette façon que sont mis en place les CI.
Dans l’exemple ci-dessus lorsque la commande git commit est appelé avant de
commit git va appelé le script pre-commit.
Pour mettre en place il est nécessaire de crée un fichier dans le dossier
.git/hook/ du nom de l’action.
Les hooks disponibles coté client sont les suivants :
- Autour des commits :
- pre-commit : avant la création du commit, avant même l’édition du message (ex. : linting, tests unitaires courts) ;
- prepare-commit-msg : avant la création du commit, au moment où l’on va avoir la main sur l’édition du message (ex. : permet l’injection d’un message pré-calculé) ;
- commit-msg : juste avant la création du commit, mais après l’édition du message (ex. : contrôle du contenu du message et réécriture à la volée) ;
- post-commit : une fois le commit crée (ex. : notification) ;
- Autour de l’application d’un patch (hooks lancés autour de la commande git am) :
- applypatch-msg : avant l’application du patch (vérification du message de patch) ;
- pre-applypatch : après l’application du patch, mais avant la création du commit (ex. : validation du contenu du patch appliqué) ;
- post-applypatch : une fois le patch appliqué et le commit créé (ex. : notification de l’auteur du patch) ;
- Autres opérations :
- pre-rebase : avant le démarrage de la commande git rebase (ex. : interdire le rebase de la branche master ou de commits déjà poussés sur le serveur) ;
- post-checkout : après l’exécution d’un git checkout et ses appels implicites, par exemple lors d’un rebase ou à la fin d’un git clone (ex. : paramétrage de l’environnement de travail associé, énoncé de la branche lors du déplacement sur une branche) ;
- post-merge : après l’exécuton réussie de git merge (ex. : vérification de la présence de marqueurs de conflits suite à une mauvaise fusion) ;
- post-rewrite : invoqué par des commande de “ré-écriture” des révisions (git commit –amend, git rebase) ;
- pre-auto-gc : lors de l’appel automatique au garbage collector (permet donc d’intervenir avant la suppression de certains objets et certaines références) ;
- pre-push : intervient juste avant l’envoi de nouvelles révisions et/ou objets vers un serveur (ex. : lancement des tests unitaires et validation/invalidation de l’envoi).
Il est possible de faire la même chose coté serveur mais je vous laisse un peu chercher.
Mettre de coter
Il est for utile dès fois de pouvoir mettre notre travail de coté comme par exemple si l’on veut récupérer un commit mais que l’on a pas terminer de développer. Il est alors possible d’utiliser la commande:
$ git stash
$Cette commande va sauvegarder le travail dans une pile comme le présente l’exemple ci-dessous:

grace à la commande git stash popon récupère le travail sauvegarder sur le
haut de la pile et si on souhaite supprimer un élément de la pile il suffit
d’utiliser git stash drop
écraser/modifier des commits
Dans certain cas des commits sont des erreur et ne devrait pas avoir été commit. On se demande alors comment les supprimer.
Pour cela il existe 2 façons de faire mais les 2 ont leurs utilités.
Reset
Si on souhaite revenir à un état précédent on utilisera git reset jusque la pour
identifier un commit on utilisait le sha mais il est possible aussi
d’identifier un commit relativement. HEAD est la tête de la ligne de
développement c’est à dire le dernier commit. Si on veut avoir l’avant dernier
on pourra utiliser HEAD~1 et ainsi de suite.
Imaginons alors notre ligne développement comme suit:

si on décide de supprimer les 2 derniers commit on va alors déplacer la tete à HEAD~2:
$ git reset HEAD~2
Unstaged changes after reset:
M test
$On se retrouvera alors dans ce cas la:

Si jamais le reset ne fonctionne pas il est toujours possible de le forcer
grace à l’option --hard
Revert
Si on souhaite au contraire seulement enlever les modifications faites par un
commit en plein milieu de la ligne de développement. On utilisera la commande
git revert:
$ git revert <commit>
error: could not revert <commit>... commit 2
hint: after resolving the conflicts, mark the corrected paths
hint: with 'git add <paths>' or 'git rm <paths>'
hint: and commit the result with 'git commit'
$revert va alors crée un commit qui fera l’inverse du commit cible.
Amend
Lorsque l’on se rend compte qu’on a commit no changement mais que le message est le mauvais ou que l’on a oublié d’ajouté un fichier ou que nos modification ne sont pas bonne rien n’est perdu il est toujours possible de modifier tout ca.
Il vous suffit d’effectuer vos modifications à vos fichiers puis de les ajouter et d’appelé la commande:
$ git commit --amend
[master <commit>] <message>
Date: Sun Apr 5 14:28:02 2020 +0200
1 file changed, 1 insertion(+), 1 deletion(-)
$si vous ne souhaitez pas modifier le message il suffit d’ajouter l’option
--no-edit
Supression seulement sur git
Un petite option qui pourra surement vous sauvez pas mal d’heures perdus
$ git rm --cached <file>
$Le fichier sera alors supprimer sur git mais sera toujours disponible en local tout n’est pas bon à ajouter à git.
Les Reflog
Git ne vous a pas encore tout dit, à chaque modification suppression de commit ou de branche vont etre sauvegardé dans les reflog permettant de si jamais vous voulez retrouver un commit perdu de le retrouver.
$ git reflog show
b05a0c5 (HEAD -> master) HEAD@{0}: commit (amend): qsqd
60a2d00 HEAD@{1}: commit (amend): qsqd
2687737 HEAD@{2}: commit (amend): qsqd
64b911f HEAD@{3}: commit (amend): qsqd
a820213 (origin/master, origin/HEAD) HEAD@{4}: commit: qsqd
13f6ab4 (origin/test) HEAD@{5}: reset: moving to HEAD
13f6ab4 (origin/test) HEAD@{6}: reset: moving to HEAD~2
0fa442c (toto) HEAD@{7}: merge toto: Fast-forward
9aa88d6 HEAD@{8}: checkout: moving from toto to master
0fa442c (toto) HEAD@{9}: commit: .
9aa88d6 HEAD@{10}: checkout: moving from master to toto
9aa88d6 HEAD@{11}: rebase finished: refs/heads/master onto 9aa88d6e388dd9f32bcaac9f41912d85c9ffc113
13f6ab4 (origin/test) HEAD@{12}: rebase:
9aa88d6 HEAD@{13}: rebase: checkout toto
13f6ab4 (origin/test) HEAD@{14}: checkout: moving from toto to master
9aa88d6 HEAD@{15}: commit: .
13f6ab4 (origin/test) HEAD@{16}: checkout: moving from master to toto
13f6ab4 (origin/test) HEAD@{17}: checkout: moving from df347da2e1db8f64207964562ea1142d66e0ad43 to master
df347da HEAD@{18}: checkout: moving from master to df347da
13f6ab4 (origin/test) HEAD@{19}: checkout: moving from 13f6ab40dcb897733df15461045786604521d05e to master
13f6ab4 (origin/test) HEAD@{20}: checkout: moving from master to remotes/origin/test
13f6ab4 (origin/test) HEAD@{21}: checkout: moving from test to master
13f6ab4 (origin/test) HEAD@{22}: checkout: moving from master to test
13f6ab4 (origin/test) HEAD@{23}: checkout: moving from toto to master
13f6ab4 (origin/test) HEAD@{24}: checkout: moving from master to toto
13f6ab4 (origin/test) HEAD@{25}: rebase finished: returning to refs/heads/master
13f6ab4 (origin/test) HEAD@{26}: rebase: .
4ae5af4 HEAD@{27}: pull --rebase: checkout 4ae5af4df8d303ca6d5a08e603a3257d841d49db
a952fa4 HEAD@{28}: commit: .
df347da HEAD@{29}: clone: from /home/bfo/Downloads/tuto_git/server/test1.git
$ # 4ae5af4 HEAD@{27}: pull --rebase: checkout 4ae5af4df8d303ca6d5a08e603a3257d841d49db
$ # 4ae5af4 est le commit qui nous interesse
$ git checkout 4ae5af4Blamer le coupable
Il est temps de blamer le coupable!

Git va permettre de connaitre qui a fais tel ou tel modification. En spécifiant le nom du fichier à la commande git blame chaque ligne sera accompagné du nom de la personne qui l’a modifié et à quel commit.
$ git blame test
b05a0c5f (Benoit Forgette 2020-04-05 14:28:02 +0200 1) Ceci est un testBisect ou retrouver le moment où tout à foirer
Il arrive des fois que notre code foire mais que l’on ne sait pas depuis quand
(enfin avec un hook qui lance une teste suite automatiquement ca ne devrait pas
arriver). Mais ca peut arriver alors il vous reste une solution git bissect.
Cette commande va parcourir tout vos commit depuis le commit valide et identifier à partir de quand il a eu un Koak.
$ git bisect start
$ # le dernier commit quand on sait que cela marcher
$ git bisect good <commit>
$ # le dernier coommit quand on sait que cela ne marcher pas souvent HEAD
$ git bisect bad <commit/HEAD>
$ # le script permettant d'identifier le Koak (si il n'y en as pas il faudra le faire à la main
$ git bisect run <script.sh>Correctif
Je ne sais pas si vous vous êtes déjà demandé si il était possible d’enregistrer un correctif sur un projet git qui n’est pas à nous et de pouvoir appliquer ou partager ce correctif facilement. Mais moi c’est une question que je me suis posé et effectivement c’est possible.
pour cela rien de plus simple il suffit d’effectuer vos modifications sur votre projet git puis de les enregistrer grace à:
git diff > <modif.patch>Maintenant il suffit de partager cette modif à qui vous voulez et de leur demander d’effectuer cette commande:
git apply <modif.patch>Pour votre culture sachez que les correctifs sur le projet linux sont faite comme ca et qu’il est possible de le paramétrer pour l’envoyer en tant que mail.
Une petite liste de ce qui vous reste à voir…
Les tags
- git tag
picorage
- git cherrypick
- git cherrypick -x
Les alias
- git config alias
Un des alias que j’ai mis qui me sers très souvent est le suivant:
$ git alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"Cette commande permet d’avoir des log plus jolie enfin depuis mon point de vu le beau est subjectif.
submodule
- git add submodule